

Quality of labelled training data is an important aspect to consider when training a machine learning model. Since machine learning model learns from the labelled data itself, the accuracy of machine learning model directly depends on the annotation quality in a supervised learning scenario. Quality of the training data is affected by label noise, which can occur due to human errors, a genuine confusion or ambiguous examples. Improving the quality of annotations in supervised learning model requires robust quality checks with multiple experienced human data annotators, hence it also increases the budget for building a robust machine learning model.
We conducted a study to benchmark model performance degradation due to label noise on a text classification task in Spoken Language Understanding (SLU) systems, and proposed mechanisms that can be deployed to mitigate the degradation. For the purpose of this study, we injected synthetic random noise ranging from 10% to 50% in the dataset and compared the performance with a model trained on clean data. To inject the synthetic noise, we randomly select x% of the utterances in the training and validation set (we call x ‘noise percentage’) and randomly flip their class labels.
Figure 1 shows the epochs vs model accuracy on both clean and noisy training data with 50% noise injected into a publicly available SNIPS dataset (Coucke, et al. 2018).
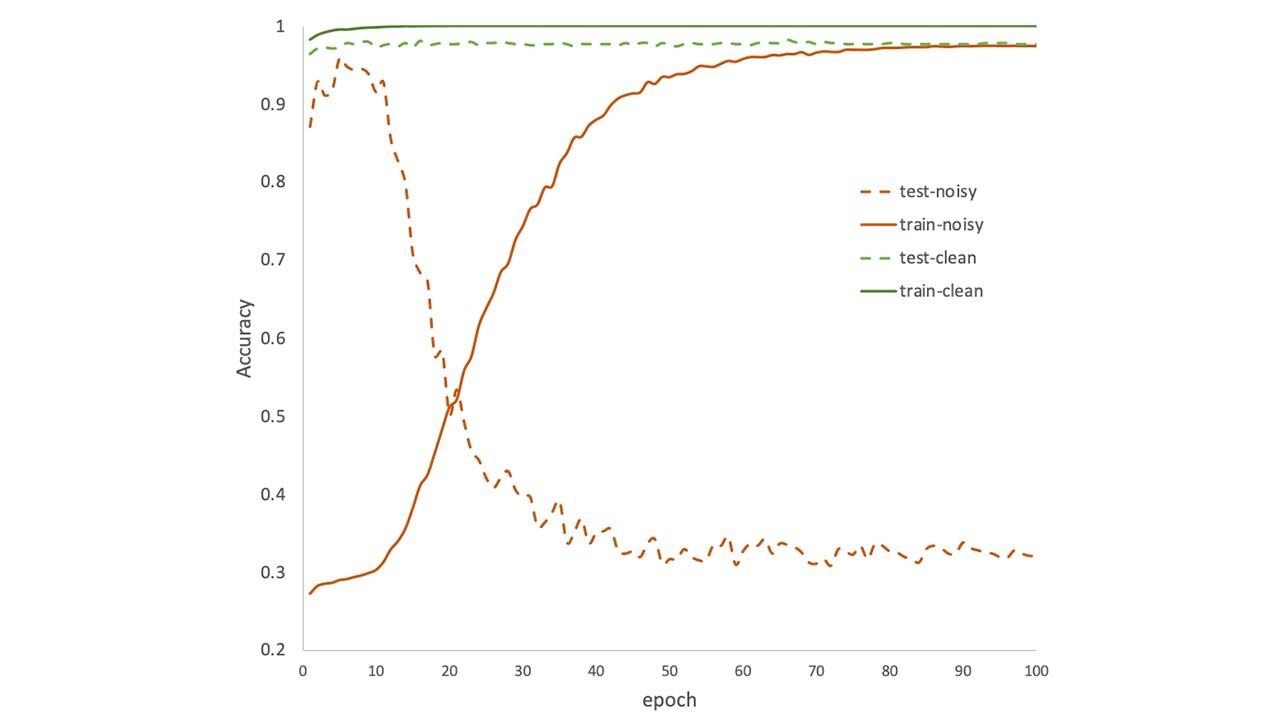 Figure 1: Learning curve for clean data and 50% noise on SNIPs dataset, where lines tagged by ‘clean’ refer to accuracy of model trained on clean data and ‘noisy’ refer to accuracy of model trained on noisy data. Please note that we always use a clean test set for reporting the accuracy numbers, i.e., ‘test-noisy’ represents performance of model trained on noisy data as tested on clean data.
Figure 1: Learning curve for clean data and 50% noise on SNIPs dataset, where lines tagged by ‘clean’ refer to accuracy of model trained on clean data and ‘noisy’ refer to accuracy of model trained on noisy data. Please note that we always use a clean test set for reporting the accuracy numbers, i.e., ‘test-noisy’ represents performance of model trained on noisy data as tested on clean data.We can see that performance of the SLU model remains coherent on clean training and test data (green solid and dotted lines). For the model trained on noisy data, accuracy on the training data keeps increasing (red solid line) as we increase the number of epochs, but accuracy on the test set decreases (red dotted line). It implies that SLU model is overfitting when training data contain noise, resulting in performance drop on the test set. It is also interesting to note that prior to overfitting (which in this case is for <10 epochs), the model performs much better in the clean test set when trained on the noisy training set, i.e., the model is able to pick up correct patterns in spite of presence of random noise in the training data.
To reduce the performance drop of SLU model due to noise on text classification task, we have studied following five mitigation methods:
Noise Layer (Jindal, et al. 2019): Noise Layer focuses on reducing the noise impact by adding a non-linear layer at the end of the Deep Neural Network (DNN). This layer differs from rest of the network in terms of different regularization and appropriate weights initialization, which facilitates it to learns the noise distribution. During inference, the noise layer is removed and the base model is used for the final predictions.
Robust Loss (Ma, et al. 2020): The method of Robust Loss proposes a loss function called Active Passive Loss (APL) which is a combination of "active" and "passive" loss functions. The former loss explicitly maximizes the probability of being in the labelled class, while the latter minimizes the probabilities of being in incorrect classes. We have used a combination of normalized cross entropy (NCE) and reverse cross entropy (RCE) loss as APL in our study.
LIMIT (Harutyunyan, et al. 2020): LIMIT is a noise mitigation method that works by adding an information-theoretic regularization to the objective function and tries to minimize the Shannon mutual information between model weights and labels. LIMIT leverages an auxiliary DNN network that predicts gradients in the final layer of a classifier without accessing label information to optimize this objective.
Label Smoothing (Szegedy, et al. 2016): Label Smoothing is a regularization technique that introduces noise in the labels to account for the fact that labelled data could have errors. Label Smoothing regularizes a model by replacing the hard class labels (0 and 1) with soft labels by subtracting small constant from the correct class and adding it to all other incorrect classes uniformly.
Early Stopping (Li, Soltanolkotabi and Oymak 2020): Early Stopping stops the training to prevent overfitting on noisy data when the model accuracy starts to decline. Error on the validation set is used as a proxy for model accuracy and training is stopped when validation error starts to increase for a certain number of epochs.
The above noise mitigation approaches fall into three categories. In the first category, training is stopped when overfitting starts, e.g., Early Stopping. The methods in the second category, e.g., such as Noise Layer and Label Smoothing, delay or reduce the impact of overfitting and can further benefit from Early Stopping. The third kind updates the loss function in such a way that model doesn’t overfit, which occurs in Robust Loss and LIMIT. Hence, we use Early-Stopping with Noise Layer and Label Smoothing but not with Robust Loss and LIMIT in our experiments.
Results on public dataset
We trained DistilBERT (Sanh, et al. 2019) model on three publicly available datasets on text classification task: ATIS - Air Travel Information System (Hemphill, Godfrey and Doddington 1990), SNIPs - personal voice assistant (Coucke, et al. 2018) and the English portion of TOP Task-Oriented Dataset dataset (Gupta, et al. 2018) from Facebook. Table 1 contains the results on all three datasets with varying noise percentages ranging from 10% to 50%.
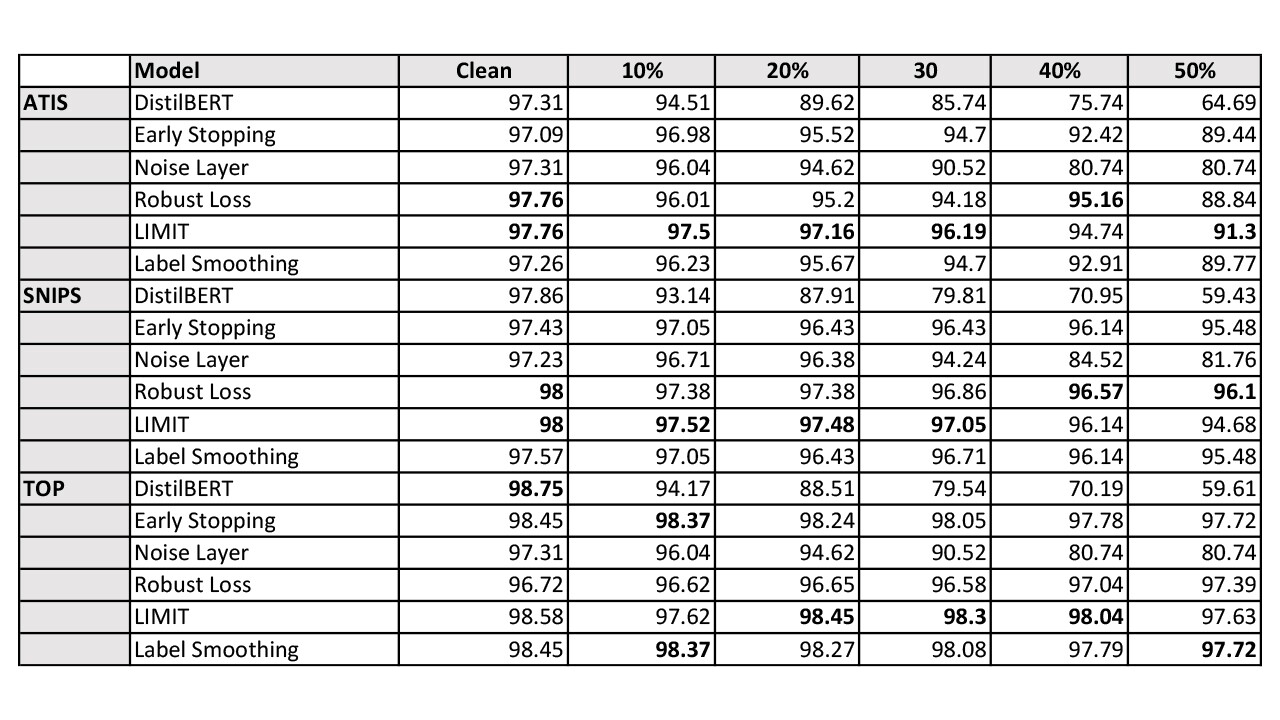 Table 1: Accuracy of various mitigation methods on public datasets. Best accuracy on clean data and noisy data is highlighted.
Table 1: Accuracy of various mitigation methods on public datasets. Best accuracy on clean data and noisy data is highlighted.Based on the results in Table 1, we observe drop in accuracy for all three datasets as the noise is added to the training data. LIMIT is able to recover most of the dropped accuracy in all three datasets, closely followed by Early Stopping. Robust Loss demonstrates the best performance on SNIPS, and Label Smoothing has the best performance on TOP dataset. We also observe improvements in the ‘clean’ ATIS and SNIPS datasets, which indicates that the publicly available datasets contain noise.
Results on industrial dataset
We applied the above mentioned mitigation methods on our industrial dataset used for text classification task under the large scale Spoken Language Understanding (SLU) system. This dataset contains textual transcripts of the spoken requests made by users on this large-scale SLU system and was pre-processed so that users are not identifiable (“de-identified”). We had access to the gold and noisy version of annotations of the same examples. The gold data goes through rigorous quality checks with multiple experienced human data annotators and has fewer or no annotation errors.
We train our mitigation methods on the noisy version and test them on the gold counterpart. For comparison, we also train model with gold annotations of the same examples and report the accuracy gain for the model. We believe that noise mitigation methods should vie to achieve the accuracy of the model trained on the gold data.
Table 2 reports the results on three domains of the industrial SLU system. Similar to intent classification task on public datasets, the domain classification task hypothesizes a target domain such as Music, Books, etc., given an utterance text. First, we note that training on the noisy data results in a measurable accuracy drop. Indeed, the last row in the Table 2 is the absolute difference in accuracy when trained on the gold data over the one trained on the noisy data, which forms a benchmark for a maximal recovery a noise mitigation method can be expected to achieve. On an average, training on the gold data has 2.69% relative improvement in accuracy. Then we look at the effect of different noise mitigation strategies. For each mitigation method in Table 2, the corresponding row represents the accuracy gap between the models trained with and without mitigation method on noisy data for three industrial domains. We see that Early Stopping performs the best and recovers 57% of dropped accuracy compared to gold data. LIMIT and Robust Loss closely follow Early-Stopping and recover 31% and 40% accuracy drop respectively.
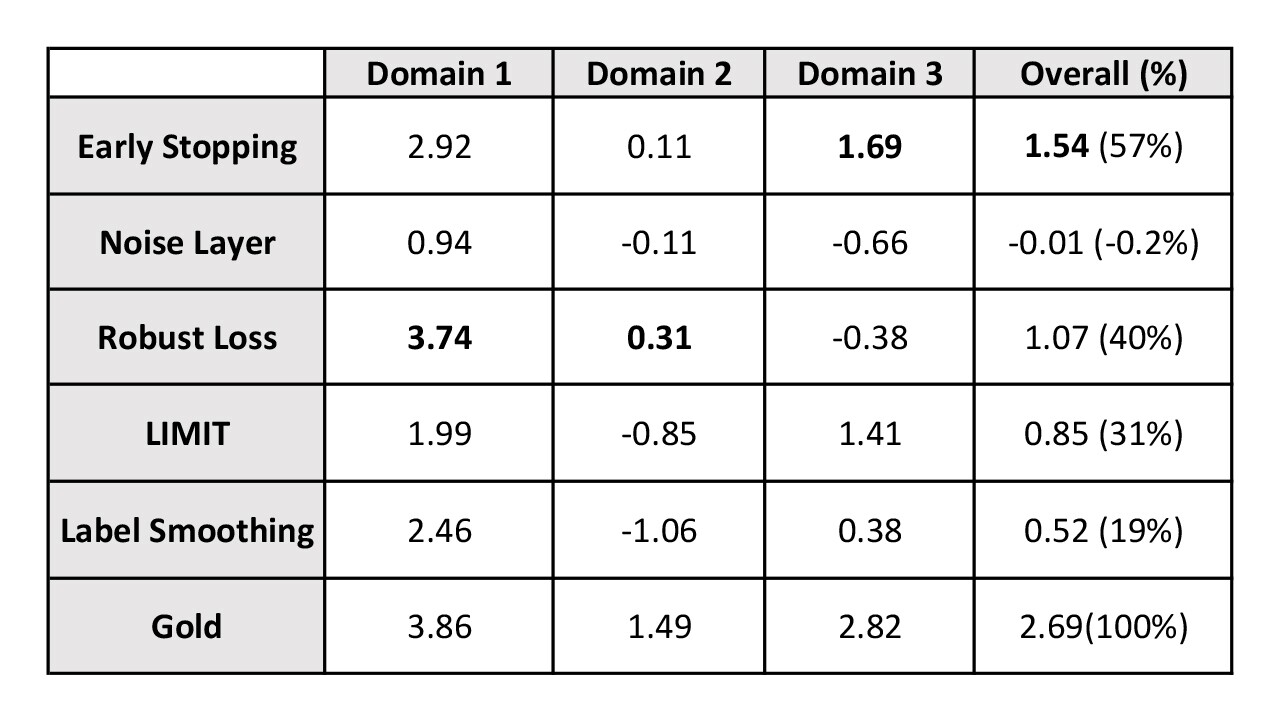 Table 2: Accuracy improvement of various mitigation methods on industrial dataset
Table 2: Accuracy improvement of various mitigation methods on industrial datasetOverall, there isn't one method that works best across the board, but we see that Early Stopping and LIMIT outperform the other methods evaluated in both public and the industrial datasets used. However, we see that even the best performing method (Early Stopping) is able to recover only about 57% of accuracy drop in the industrial setting while we observe up to 98% performance recovery on randomly-injected noise in public datasets. This might be due to the fact that the label noise distribution in real-world dataset is more complex than the simple random noise model considered in this study. Hence, there is further scope of improvement to build noise-robust systems for real-world noise. It is an interesting open problem to characterize the noise distribution in real systems and devise better mitigation strategies tailored to such noise models, which we will consider as future work.
For more details, please follow our research paper published in Industry track at Interspeech, 2022 “Learning under Label Noise for Robust Spoken Language Understanding Systems”.







