

As an aspiring marathon runner, I am always looking for new and engaging podcast content to listen to while pounding the pavement. However, its often challenging to find a podcast that I enjoy. Since the podcast’s title or description doesn’t always accurately reflect the quality of the content, I spend about 15-20 minutes listening to a podcast only to realise that it’s not what I was looking for. What if there is a way to get a meaningful yet concise summary and using that as a criterion to select the podcast? Well, there is!
This blog will explore how to combine multiple AI tools from Amazon to generate a concise summary of any podcast and extract insights in a few minutes. Amazon Bedrock, Amazon Transcribe and A Large-Language Model (LLM) are some of the tools that will used for this purpose. Amazon Bedrock is a fully managed service that makes high-performing foundational models accessible via a single API, along with a set of capabilities to build generate AI applications. Amazon Transcribe is a fully managed automatic speech recognition service that enables users to ingest audio and produce easy to read transcripts. A Large-Language Model (LLM) is a general-purpose, probabilistic, natural language model that can be used for language understanding and generation.
We will start with an assumption that the reader has a basic understanding of terms such as Generational AI, LLM, and some of the AWS services such as Amazon SageMaker, Amazon Transcribe and Amazon S3. The content of this blog is aimed at individuals seeking to learn and explore Generative AI using Amazon Bedrock. Any use of the technique demonstrated in the blogpost shall be restricted to personal and non-commercial use only.
Solution Architecture
In this section let us look at the Solution Architecture for the demo setup.
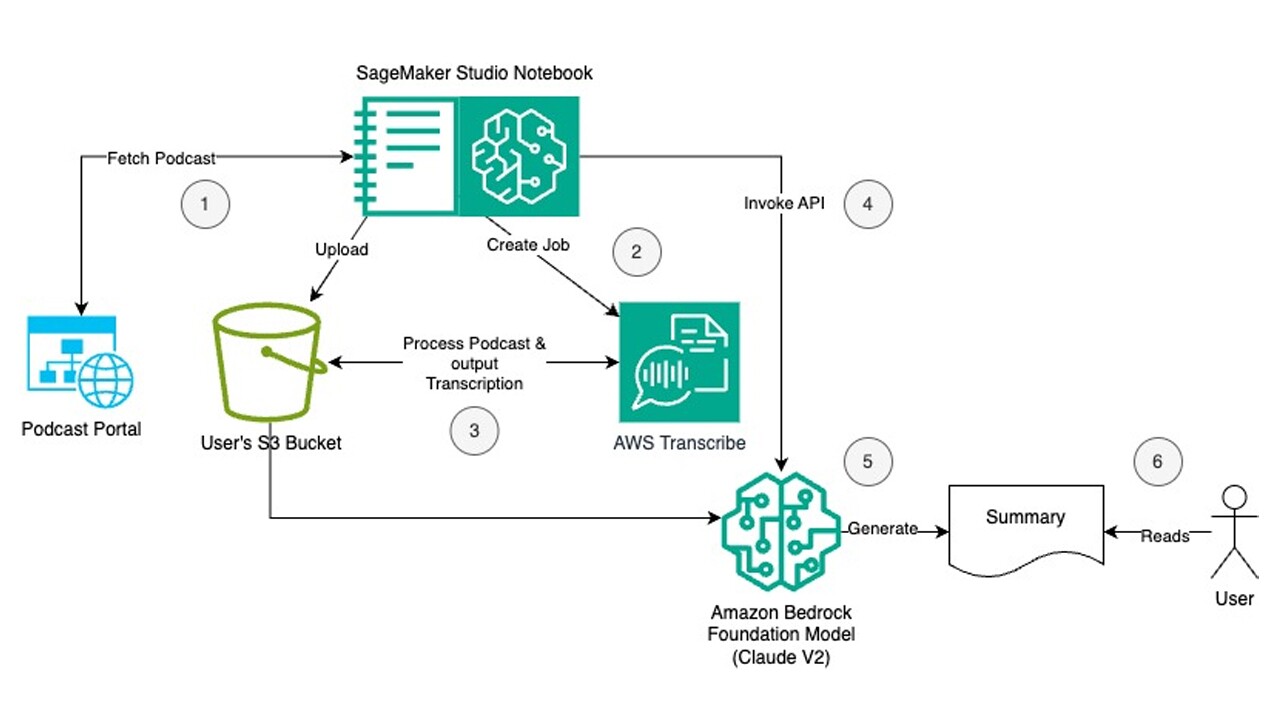
Steps:
- Using SageMaker Studio Notebook, a publicly available podcast is fetched from the podcast source and uploaded to an S3 bucket, a cloud storage solution by AWS.
- From the SageMaker Studio Notebook, a Transcribe job is created using Amazon Transcribe API to automatically convert speech to text. Amazon Transcribe is an AWS AI service that automatically converts speech to text.
- The output of successful completion of the job is a JSON file that contains the text extracted from the podcast file. The JSON file is stored in the same S3 bucket under 'out' folder.
- The output JSON file is read and the text is extracted in the Studio Notebook instance's memory. An instance of Anthropic Claude V2 model is created using Amazon Bedrock API. In the session below we explain why this particular LLM foundational model was selected for the summarisation task.
- Using prompt engineering, the model is instructed to summarise the extracted podcast text and list the output in bullet points. User can read the LLM model’s response, which is a summary of the podcast.
- Optionally, the user can modify the prompt or tune the LLM model's inference parameters to derive further insights. Using Bedrock's streaming API, the response from the LLM model is streamed in chunks and displayed to the user in order to reduce the waiting time.
Prerequisites
For the demo solution demonstrated in this article, the following prerequisites are required:
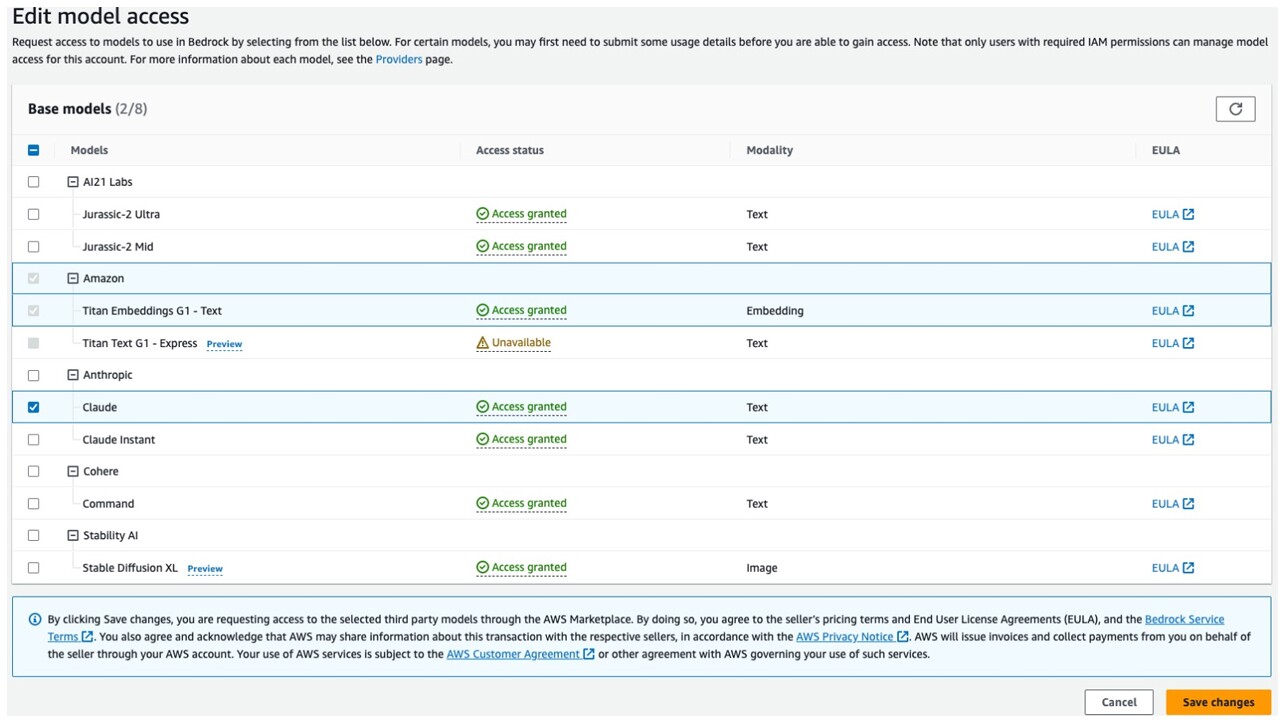
- An AWS account with access to Amazon Bedrock service. Ensure model access to Claude is enabled as shown below. This setting can be enabled by navigating to Amazon Bedrock console<Model Access page.
- An S3 bucket with all public access disabled.
- Install the prerequisites libraries on the SageMaker Studio Notebook using the following commands.
pip install --no-build-isolation --force-reinstall \ "boto3>=1.28.57" \ "awscli>=1.29.57" \ "botocore>=1.31.57"%pip install langchain==0.0.309 "transformers>=4.24,<5"%pip install tiktoken
Demo
In this section, we will go over the steps involved in the demo solution in bit more detail. The SageMaker Studio Notebook file that is used to prepare this demo is available on GitHub here. In the first step, the podcast MP3 file is saved to the Studio Notebook instance and then uploaded in to an S3 bucket as shown below. I have downloaded a podcast on Herman Melville’s epic novel Moby Dick using the below command. This podcast has been sourced from RadioOpenSource under creative commons license and the terms are accessible here.
!wget -O podcast.mp3 http://www.brown.edu/Departments/Watson_Institute/Open_Source/RadioOpenSource-Harold_Bloom-Melville.mp3
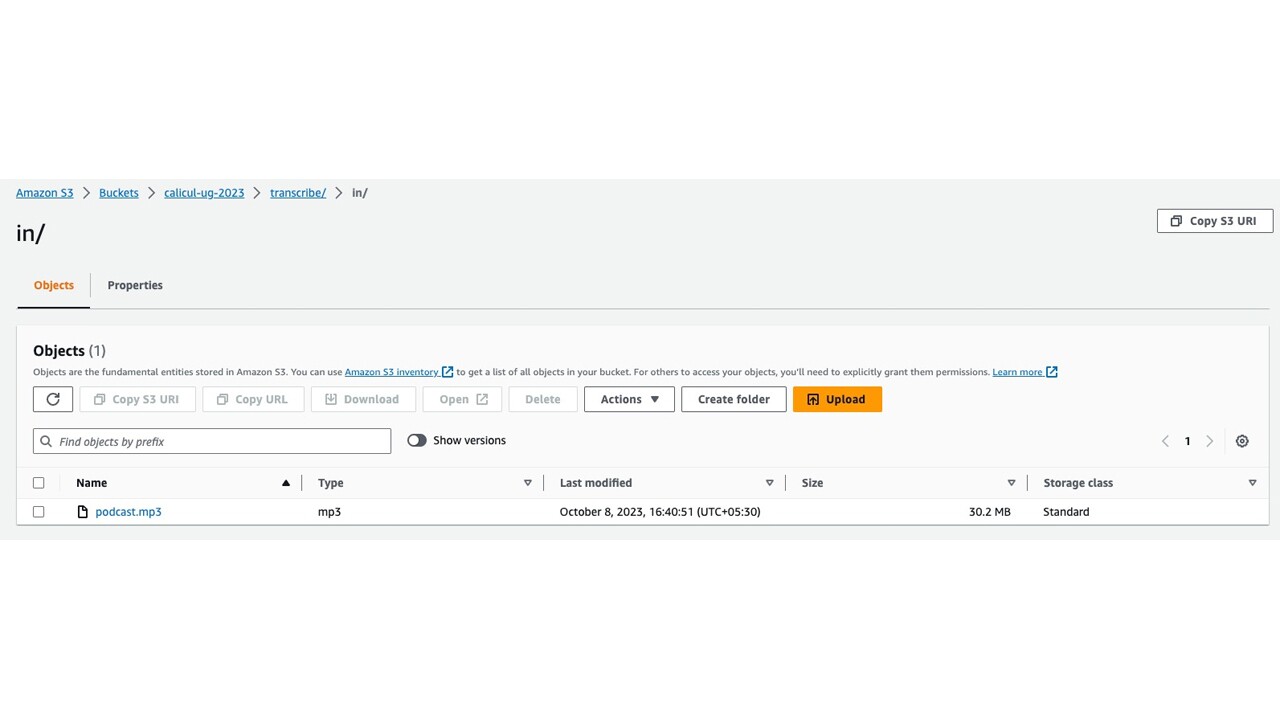
The podcast length is approximately 36 minutes. Next, the podcast.mp3 is uploaded to my S3 bucket and verified as shown below.
import boto3s3_client = boto3.client('s3')file_name = "podcast.mp3"bucket = "calicul-ug-2023"object_name = "transcribe/in/podcast.mp3"response = s3_client.upload_file(file_name, bucket, object_name)
Now we import the required libraries.
import jsonimport osimport sysimport sagemakerimport timeimport jsonimport warningsimport langchainwarnings.filterwarnings('ignore')
Start a Transcribe job that reads the podcast mp3 file from the S3 location and outputs a JSON file that contains the transcription.
transcribe = boto3.client('transcribe')job_name = "transcribe_podcast"job_uri = "s3://calicul-ug-2023/transcribe/in/podcast.mp3"output_loc = "transcribe/out/"response = transcribe.start_transcription_job( TranscriptionJobName=job_name, Media={'MediaFileUri': job_uri}, OutputBucketName=bucket, OutputKey=output_loc, MediaFormat='mp3', LanguageCode='en-US')
Await for the Transcribe job to be completed. If the job succeeds or fails, exit. If not, keep querying the Transcribe job status API for a maximum of 600 seconds.
max_tries = 60while max_tries > 0: max_tries -= 1 job = transcribe.get_transcription_job(TranscriptionJobName=job_name) job_status = job['TranscriptionJob']['TranscriptionJobStatus'] if job_status in ['COMPLETED', 'FAILED']: print(f"Job {job_name} is {job_status}.") if job_status == 'COMPLETED': print( f"Download the transcript from\n" f"\t{job['TranscriptionJob']['Transcript']['TranscriptFileUri']}.") break else: print(f"Waiting for {job_name}. Current status is {job_status}.") time.sleep(10)
Once the job has executed successfully (takes about a minute), the following information is shown.
Waiting for job_name. Current status is IN_PROGRESS.Job job_name is COMPLETED.Download the transcript from https://s3.us-east-1.amazonaws.com/calicul-ug-2023/transcribe/out/transcribe_podcast.json.
As we inspect the S3 output folder and the output JSON file, we find the following information.

Now that the job has run successfully and the transcription has been completed, next we extract the text data attribute from the JSON file and store it in the Notebook instance's memory. Print the first 500 characters to verify whether the text was loaded successfully.
s3 = boto3.client('s3')key = 'transcribe/out/job_name.json'response = s3.get_object(Bucket=bucket, Key=key)data = json.loads(response['Body'].read().decode('utf-8'))text = data['results']['transcripts'][0]['transcript']print(data['results']['transcripts'][0]['transcript'][:500])
I'm Christopher Lydon, heading into Harold Bloom's class at Yale on the American masterpiece, Moby Dick. This is open source from the Watson Institute at Brown University, an American conversation with global attitude. We call it Harold. It's amazing to me. We've never talked about the Great Melville or the Great Moby Dick on the way to class said it in your blooming framework. Well, there won't be time to talk to the Children about this today because I want them to read out loud from Moby Dick.
We have to choose an LLM Model with a context window large enough to allow processing of the number of tokens that Transcribe has extracted from the podcast. Tokens are fragments or parts of words. We can think of tokens as either a word or part of a word. The overall ratio of tokens per word varies from model to model. Many common words could be represented as a single token, while less common words might contain multiple tokens. We can get the number of Tokens embedded in the text output of Transcribe job. For this demo, we use the tiktoken library to get the Token count.
encoding = tiktoken.get_encoding('cl100k_base')num_tokens = len(encoding.encode(text))num_tokens
We have 5584 tokens in our text. Let us look at the Amazon Bedrock documentation to choose an LLM Model which can accommodate the number of tokens in the text input. Amazon Bedrock offers a broad range of foundational models from aI companies like AI21 labs, Anthropic, Cohere, Meta, Stability AI and Amazon. Reviewing the documentation related to the inference parameters for the supported foundational models, we can see that Anthropic Claude LLM has a 100K long context window. We find that Anthropic Claude V2 LLM model with a 100K context window (75,000 words) will be sufficient for our summarisation task. Let us now define a prompt that provides sufficient instructions to the LLM model to perform the summary task. In this case we want the Model to provide a concise summary of the input that is limited to 1000 words. The summary should be listed as bullet points. We codify this instruction in to a prompt body as shown below. Observe the inference parameters that we have set for the Claude V2 model. Tweaking the inference parameters will allow us to provide dynamic instructions to the LLM model which would result in varied outputs. In our case, we set the temperature to 0.1 (to reduce the degree of randomness in the response) and max tokens to sample to 1500 (the maximum number of tokens to use in the generated response).
prompt = "Human: Summarize the following text in a concise manner. Limit the response to 1000 words. Write the response in bullet points. \\n\\n"""+ text + "\\n\\nAssistant:"body = json.dumps({ "prompt": prompt, "max_tokens_to_sample": 1500, "temperature": 0.1, "top_p": 0.5})
Finally, let us pass the prompt body to the Claude V2 LLM model and wait for a response. It takes about 30-40 seconds for the model to return the response.
modelId = 'anthropic.claude-v2'accept = 'application/json'contentType = 'application/json'response = bedrock.invoke_model(body=body, modelId=modelId, accept=accept, contentType=contentType)response_body = json.loads(response.get('body').read())print(response_body.get('completion'))
The response is as follows.
Here is a summary of the key points from the text in bullet points:- Harold Bloom considers Herman Melville and Walt Whitman to be the two greatest figures in American literature. He sees Moby Dick as an almost flawless "prose epic" on par with the best of Shakespeare. - Ishmael is the biblical name of Abraham's disinherited son, indicating Melville's humorous bitterness at his own family's fallen status. Ishmael is an unreliable narrator who sometimes vanishes from the story.- Captain Ahab represents defiance against God's tyranny over nature and humanity. His obsession with vengeance on the white whale echoes the biblical King Ahab's conflicts with the prophet Elijah.- The white whale symbolizes the blankness or meaninglessness of nature and the universe. This trope of whiteness haunts much of American literature.- Though the whalers are Quakers, the hunt seems unfair and horrifying. There is an inverse ratio between the trope of whiteness and the paradox of these "killers" being pacifists.- Moby Dick engages with the biblical Book of Job and its depiction of the tyrannical Leviathan. Ahab seeks to strike out against this image of God's domination.- The book draws on gnostic and hermetic traditions that envision slaying the Leviathan as liberation. It expresses outrage at monotheism's sanctification of divine tyranny.
As we can observe, the LLM model was able to summarise a 36-minutes long podcast to a less than 1000 words. While the evaluation of the LLM model for summarisation task is beyond the scope of this blog, here are few ways in which we can evaluate the outcome. We can use ROUGE scores by comparing the model summary with human-written summary. We can also use human raters to score the model for coherence, fluency, length, redundancy and coverage of important details from the original text. By averaging the ratings across raters we can interpret the model’s summarisation task efficiency.
Additionally, we can also interact with the podcast in creative ways to get additional insights. Using prompting techniques, we can ask the LLM model to provide contextual information pertaining to the podcast content. In this example, we ask the LLM model to mention the people referred in the podcast.
prompt = "Human:List the top 3 characters in the text and explain their role. \\n\\n"+ text + "\\n\\nAssistant:"
Claude v2 responds with the following:
Here are the top 3 characters in Moby Dick and their roles:1. Captain Ahab - The monomaniacal captain of the Pequod who is obsessed with getting revenge on the white whale Moby Dick that bit off his leg. He is driven by vengeance and his quest consumes him. 2. Ishmael - The narrator of the story. He signs up for a whaling voyage on the Pequod to escape his depression and melancholy. He is philosophical and reflective. As the sole survivor of the voyage, he lives to tell the tale.3. Moby Dick - The great white whale that is the object of Captain Ahab's vengeance. While a literal whale, he also serves as a symbol of nature, the mysteries of the universe, evil, and more. His whiteness and elusiveness maddens Ahab.In summary, Ahab is the crazed captain seeking vengeance, Ishmael is the contemplative narrator, and Moby Dick is the whale that drives the plot through the obsessive hunt by Ahab. Their interplay and motivations shape this epic story of man versus nature.
In another example, let us try a different approach of getting a response from the LLM model. In the previous two examples, we have used a non-streaming approach where we pass the prompt to the LLM model and we wait for the response. In this example, let us try a streaming approach where the response from LLM model for the prompt is processed as streams and can be displayed to the user as it is being generated. In this example, we prompt the model to explain the reasons behind Captain Ahab’s (one of the key characters in the novel) vengeance against Moby Dick as explained in the podcast. The prompt and the response are listed below.
prompt = "Human:Explain Ahab's vengeance against Moby Dick. \\n\\n"+ text + "\\n\\nAssistant:"body = json.dumps({"prompt": prompt,"max_tokens_to_sample": 1500,"temperature": 0,"top_p": 0.99})modelId = 'anthropic.claude-v2'accept = 'application/json'contentType = 'application/json'response = bedrock.invoke_model_with_response_stream(body=body, modelId=modelId, accept=accept, contentType=contentType)stream = response.get('body')if stream: for event in stream: chunk = event.get('chunk') if chunk: chunk_json = json.loads(chunk.get('bytes').decode()) print(chunk_json["completion"], end='')
Here are a few key points about Ahab's vengeance against Moby Dick in Herman Melville's novel:- Ahab is the monomaniacal captain of the whaling ship Pequod. He is obsessed with hunting and killing Moby Dick, the great white whale that bit off his leg in a previous encounter. - Moby Dick represents many things to Ahab - the embodiment of evil, a force of nature, an affront to Ahab's power and authority. The whale's whiteness and seeming invincibility maddens Ahab. - Ahab sees hunting Moby Dick as his great purpose and destiny. He believes the whale is an agent of cosmic malignity that must be destroyed. His quest is both personal vengeance and a defiance of the powers that seem to limit man. - Ahab's obsession drives him to push his ship and crew to their limits in pursuit of the whale, ignoring all warnings and omens. He believes he is locked in a fateful contest with the whale that only one can survive.- The pursuit of Moby Dick leads to the demise of Ahab and his crew, except for the narrator Ishmael. Ahab's single-minded vengeance results in catastrophe, suggesting the futility of trying to contend with forces beyond human control.- Ahab's doomed quest can be seen as a metaphor for human overreach and hubris. His defiance of nature and the gods echoes mythic heroes and Biblical figures, but leads only to ruin. The white whale remains an inscrutable, unconquerable force.In short, Ahab's monomania and desire for vengeance on Moby Dick, while understandable given his injury, leads him and his men to their doom, underscoring the inability of humans to bend nature or the cosmic order to their will.
Using prompting techniques as illustrated above and by tweaking the inference parameters such as temperature, max_token, we can extract some creative and useful insights from the podcast.
Summary
In this post, we demonstrated how to extract summaries from podcast using Amazon Bedrock, Amazon Transcribe and Amazon SageMaker Studio. Amazon Bedrock’s foundational models allow users to build applications and solutions to automate the summarisation of podcasts. Users can extend this approach by batching a set of Transcribe jobs and using Amazon Bedrock API to derive concise summaries from multiple blog post and catalogue them. We can further extend this solution by storing the vector embedding of the summaries in a vector database such as Amazon OpenSeach Vector Engine and using cosine similarity to search for similar podcasts. This would allow users to search beyond keywords and find podcasts that share similar attributes such as speakers, context, location, and semantics. The solution in this blog post demonstrates the art of possibility. This solution can be developed as a product by building a web or mobile app that is hosted using Amazon Amplify. The app’s backend can be developed using serverless services such as AWS Lambda or using container orchestration service such as Amazon ECS or Amazon EKS and consumed as an API using Amazon API Gateway.







