


Objective
The purpose of this blog is to provide details of Batch and Stream based processing and guidelines to consider them in the design. Developers should consider the guidelines mentioned in the document while selecting batch or stream or a combination of both for potential solution of the problem.
Please note that not all the points of the guidelines need to match with the requirements for the selection; partial match may also be good enough to take call. Additionally, apart from the guidelines mentioned in the document, developers should also consider merit of the problem in the selection of a particular processing. There can be cases where requirements of the problem satisfy some guidelines of both Batch and Stream processing. In such cases, developers should apply their judgement by considering the more pressing requirement.
1. What is Batch Processing?
Batch processing is a way of processing high-volume data, where data is collected, stored, and processed in batches, usually at regular intervals or on demand. A “batch” is a group of events or data points collected within a given time period typically in hours or days.
A few use cases of batch processing are as follows:
- Payroll: Payments in payroll systems are disbursed to employees at the end of the period (usually weekly or monthly). The computation of the payments to be disbursed is performed periodically and the funds are procured accordingly. Even the reimbursement claims are disbursed in batches post auditing. Reporting and reconciliation of expenses are performed at the end of financial cycle in batches.
- Inventory Management: Several processes in inventory management of e-Commerce/manufacturing depends on demand forecasting based on past customers behavior, upcoming high velocity events like festival seasons, day or month of the year, product review, geographic location etc. to determine optimal levels of products to be maintained in warehouses. This requires collecting structured and semi structured data across different sources like product catalog, customer orders, product reviews and perform analysis or run machine learning algorithms to generate demand forecasts for the products. Due to the volume of data and the nature of analysis such processing is generally done in batches.
Example Design of Batch Processing
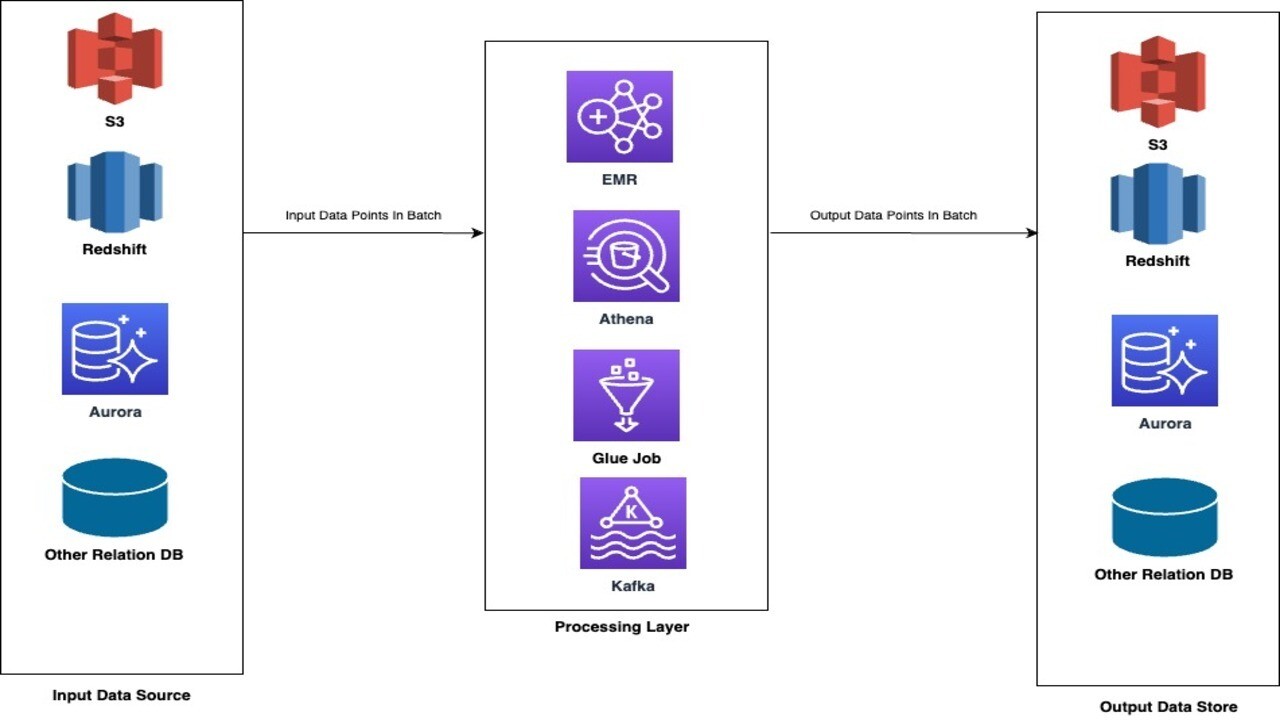
Advantages of batch based processing are as follows:
- Efficient use of compute: Because of big data, the compute is used efficiently as the individual instances do not sit idle during processing. Typically due to predictable workloads during batch processing most of the capacity of the compute instances are fully utilized.
- Simplicity in terms of infrastructure maintenance: Maintenance of the resources and stack is simpler for batch processing. This is because of the fact that data does not flow in real time and hence there is no need to re-adjust the capacity on a frequent basis. As the processing is in batch, fluctuation in data volume is averaged out and hence resource capacity fluctuation is not frequent.
- Ease and flexibility of generating analytical reports: Batch processing makes it easy to generate reports at multiple grains (or dimensions). It also improves the quality of output data due to availability of multiple updates for the same event accumulated over a period of time. It also enables easier generation of reports on historical data, which will otherwise require backfilling and/or re-processing events one by one. For e.g., If someone works in transportation finance and needs to create a financial report at carrier and country level over a month of data then it can be easily implemented using batch processing. Furthermore, if the requirements change and another report (including historical events) is required at the grain of carrier, country and business type then it does not require any backfill if the additional attributes (here business type) are available in the historical dataset.
Some limitations of batch based processing are as follows:
- High processing time and lack of responsiveness: As batch processing involves processing of data in bulk, processing time is always high. We cannot expect the processing to finish in few milliseconds or seconds. One can also not expect the response from a batch process in real time. The processes execute on a group of data points leading to generation of output over the accumulation period for all the events together.
- Risk of zero output for partial failure: In batch processing if an unhandled error appears even for 1 event then it leads to failure of complete process and blast radius of such failures will impact all the events in the batch. This further results in re-execution of the complete job to generate the output. This is a problem if the availability of data is critical within a defined SLA.
- Larger compute requirement: Because of bulk nature of data, batch based processing often requires larger compute instances and cluster. Unlike stream based processes, it cannot execute with a small cluster running all the time resulting in the procurement of high-end server instances. However, it does make optimal use of the overall computation power and typically due to reduction in wastage compute cost is less in the long term.
2. What is Stream Processing?
Stream processing is the act of processing an event or a data point as it is being generated. The processing is done either in real time or in near real time. Stream processing is either at individual data point level or over a small set of data points level collected over a few seconds or minutes.
A few use cases of stream processing are as follows:
- Delivery and its Tracking: Delivery and its tracking in transportation companies often deals in stream where each customer has the ability to place request to deliver packages individually. This is applicable in terms of package delivery and tracking among other use-cases. Even customer support for issues in delivery delays, lost packages etc. deals at per request level and not over a bulk of packages at once.
- Social Media: Operations like post view counts, like counts, subscription counts in social media platforms work at near real time. Hence they are stream based processes.
Example Design of Stream Processing
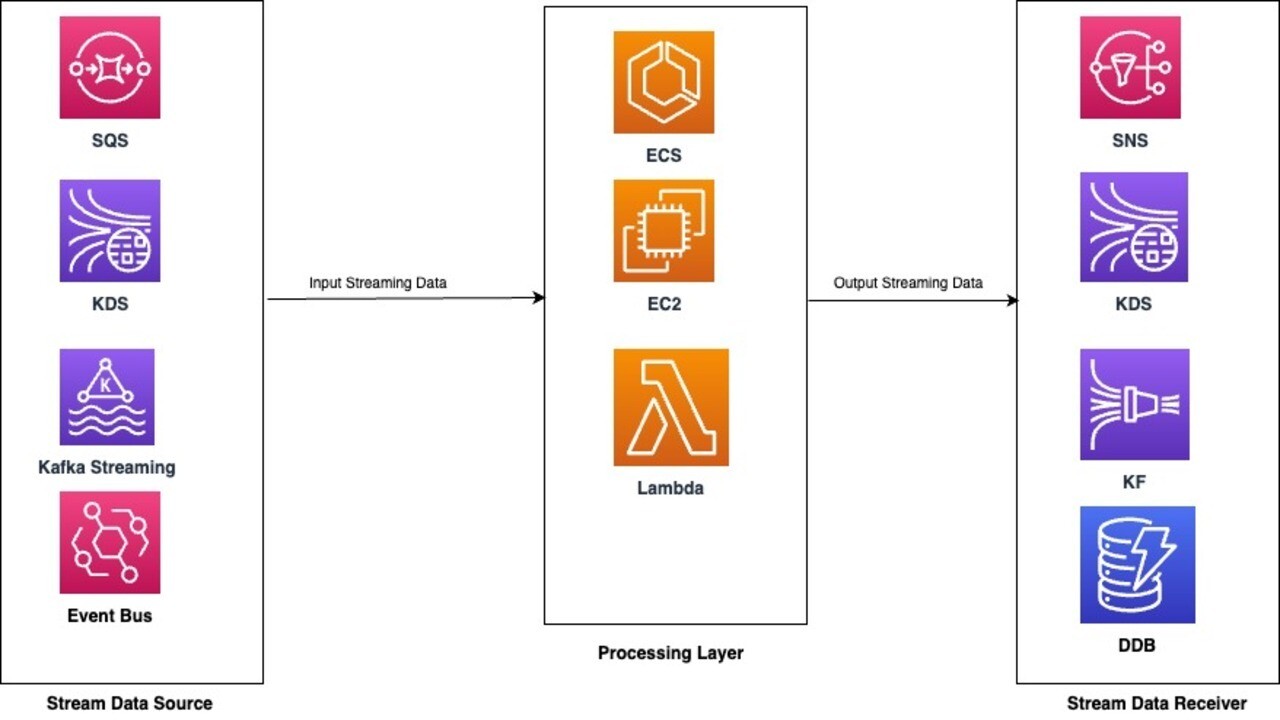
Advantages of stream based processing are as follows:
- Low processing time: As the nature of stream based processing is to process either individual event or a small set of events, processing time is always low. We do not expect processing time of hours or days for such use cases.
- Availability of latest information: One can expect the output from stream based processing in real time or near real time. Also as events are processed in near real time, any issue with the processing of event can be identified earlier, as soon as the event is generated. This can help in early fixing of the issues as well.
- Smaller compute requirement: A stream based processing can be be kick started with smaller compute instances and cluster sizes with long running processes handling events in real time. Consequently it doesn’t require high-end server instances.
Some limitations of stream based processing are as follows:
- Handling out of order or missing events: Since each event is processed individually, it needs to handle the dependencies and out-of-order processing of events which makes the system relatively more complex. This is because all the dependent events or earlier versions of the events may not be available at the time of processing.
- Maintenance of queryable state: Handling of out of order and missing events typically will require maintaining queryable states of the events in indexed storage resulting in higher cost. For e.g. if an event for the payment of order is ingested before the actual order event then we may need to store the payment event in a separate queryable store to match it against the future order event.
- Complexity in concurrency and error handling: It is difficult in stream based process to ensure fault tolerance and consistency in case of concurrent event from multiple sources. Because of processing at transaction level, it can cause intermittent failures for different sources due to incorrect ordering of events or unavailability of events. For e.g., If a synchronous system X receives one create request of a transaction A from service Y and an update request over A from service Z then it will result in intermittent failure for service Z for updates if Y failed to create transaction A before update request is made by Y. Solving such scenarios may require defining ordering of events, optimistic locking, retry strategies considering worst possible cases etc.
3. Scenarios for Batch Based Processing
3.1 Guidelines
Use batch based approach if,
- Data volume is high: Batch based processing should only be used when data is in bulk i.e. somewhere in the range of 10s or 100s of GBs at least. If the data volume is few GBs, one should rethink before going with batch processing.
- Loading full dataset is justified: One should only choose batch based processing if there is a genuine need to process/load bulk data of hundreds of GBs with high compute cost. If the processing can be completed with a few GBs of data, the data range should not be increased for the sake of choosing batch based approach.
- There is no strict SLA and high processing time is acceptable: One should only choose batch based processing if there is no strict SLA of data processing and timely availability of data is not critical. If the output of processing has to be made available to the customers by period X and batch processing has a risk of missing availability of significant chunk of the output then one should evaluate choosing stream based processing instead.
3.2 Case Studies
In this section, we will discuss a few design case studies where batch based solution is recommended.
Please note that the reader should only consider the core problem of the case studies and assume that all the required data to solve the problem are already available.
Please note that the reader should only consider the core problem of the case studies and assume that all the required data to solve the problem are already available.
3.2.1 Case Study 1
Problem
Bob is a retailer. He owns an e-commerce website with considerable sale. In order to get a sense of the sale and the revenue getting generated, he requests his team to develop a mechanism/system which generates report over a certain frequency (like daily, monthly etc.). The average number of orders per day is 10 million and the volume of the data generated is 150 GBs in a day. Also, there is a chance of duplicate data because of distributed systems generating raw data based on order creation events and their processing states.
Bob is a retailer. He owns an e-commerce website with considerable sale. In order to get a sense of the sale and the revenue getting generated, he requests his team to develop a mechanism/system which generates report over a certain frequency (like daily, monthly etc.). The average number of orders per day is 10 million and the volume of the data generated is 150 GBs in a day. Also, there is a chance of duplicate data because of distributed systems generating raw data based on order creation events and their processing states.
Additionally, Bob wants frequency of the report generation and granularity of the report to be kept flexible. This means that Bob can request for a report at product category level, for e.g. Beauty, Books, Electronics etc. or a report at product category and size combination, for e.g. Electronics of size Small, Medium, Large etc. He also can ask for such reports to be generated, weekly or daily for different business reasons and product categories.
In the report information like total order count, total sales, total revenue generated, total expense, unique customer count should be present.
Strategy
This problem is an ideal use case of batch based solution. Following are the reasons for the same:
This problem is an ideal use case of batch based solution. Following are the reasons for the same:
- Bob does not require real time visibility. Also there is no strict SLA.
- Data to be used for the report generation is huge and can be processed in batch.
- Given the grain of reporting has to be flexible, if a stream based process is chosen then creating historical reports will be complex due to a) storage and re-drive of past ordering events, b) maintaining separate environment for the creation of such reports to avoid interfering with the current production workload.
- Reporting requirement is to summarize the sales information using ordering events, which involves aggregation and unique counts over a huge amount of data which becomes complex and compute intensive for stream based solution.
3.2.2 Case Study 2
Problem
Jennifer owns several sort centers (buildings) where incoming vehicles (trucks, vans) having thousands of packages arrive, these packages are scanned and sorted, then loaded to an outgoing vehicle. For this, various machines have been installed to automate some of these activities in sort centers. These machines have costed her hundreds of thousands of dollars and have a life expectancy of 5 years including free servicing.
Jennifer owns several sort centers (buildings) where incoming vehicles (trucks, vans) having thousands of packages arrive, these packages are scanned and sorted, then loaded to an outgoing vehicle. For this, various machines have been installed to automate some of these activities in sort centers. These machines have costed her hundreds of thousands of dollars and have a life expectancy of 5 years including free servicing.
She has also hired employees for each sort center to operate these machines and perform other manual activities needed for the entire operational process. These employees are paid their salary every month.
Along with machines’ cost and employees’ salary, other operating costs to run the business include electricity bill, building maintenance cost, safety instruments, medical bills, insurance claims etc.
Close to 100K packages arrive in each sort center on a daily basis and each sort center operating cost is approximately $2M per month. Jennifer wants to understand cost of handling individual package and categories of packages in sort centers precisely. These categories can be on the basis of content (dangerous goods, pharmacy, perishable goods etc.) and size (small, medium or large bag or box) of a package. Cost of handling a package is based on time spent on each package by the employees and other resources utilized by the package in the sort center. The insights can help Jennifer to slice and dice data for operational improvements, opportunity to install additional machines to reduce cost and strategize her future business roadmap by prioritizing certain categories of packages providing higher ROI. The accuracy of knowing the cost for each package is very important otherwise it may result in bad strategic investments which will be high and take Jennifer’s business towards downward spiral.
Strategy
The reasons to choose batch based approach are as follows:
The reasons to choose batch based approach are as follows:
- The data elements to provide such an insight is not available in real time. Most of the costs to be allocated are only available by the end of the month, like employees having monthly salaries, fixed charges like electricity bill, building insurance etc. Even depreciation cost of the machinery is difficult to get in real time.
- Moreover, inaccurate and incomplete allocation of cost at package level can result in inaccurate insights which will be expensive for the business. To be more specific, allocation of incomplete cost can lead to lower cost getting assigned to individual packages. Similarly, allocation of complete cost to partial set of packages will lead to higher cost getting allocated to individual packages. Hence availability of complete information before the start of allocation is very important to achieve desired business results.
4. Scenarios for Stream Based Processing
4.1 Guidelines
Use stream based approach if,
- Request and response expectation is at event level: Stream based processing is recommended if the incoming event is readily available individually and the response is expected to be provided for individual events or a set of events aggregated over a small period of time in a micro-batch (say 1 mins or 5 mins). It is possible to accumulate and segregate data at request and response layers and choose batch based processing, but other factors will play a part to trade-off against added complexity of accumulation/segregation.
- There is strict SLA and low processing time is expected: Stream based processing of data should be chosen if availability of data within a certain period is critical. e.g., if it is critical to provide data to stakeholders within 1 hour then one should process each transaction individually rather than having a batch based process at the end of the hour. Batch process is problematic here because if there is any failure while processing the data by the end of the hour, it will result in not providing any output to stakeholders and the blast radius will be high, whereas stream processing will be having more chances of success for individual events.
- Lookup over indexed data is enough: One should go with stream based processing if there is no need to lookup over a huge set of unindexed data, otherwise additional indexes has to be created which will result in additional cost. Here unindexed data refer to data which is not stored against a particular key or set of keys and is not queryable without iterating the entire dataset.
4.2 Case Studies
In this section, we will discuss a few case studies where stream based solution is recommended.
4.2.1 Case Study 1
Problem
Mani is the head of fraud detection department of a credit card company. He owns two software components which helps the company to identify fraudulent transactions and take necessary actions. The first one is for proactive detection of fraud and declining the card transaction. The second one is for reactive detection of fraud, confirming with the customers via call/sms and blocking the card in case of fraud. These software components use machine learning techniques which requires creating models using historical data of credit card transactions. A transaction processing system invokes the first component before approving a card transaction and emits the event for reactive detection.
Mani is the head of fraud detection department of a credit card company. He owns two software components which helps the company to identify fraudulent transactions and take necessary actions. The first one is for proactive detection of fraud and declining the card transaction. The second one is for reactive detection of fraud, confirming with the customers via call/sms and blocking the card in case of fraud. These software components use machine learning techniques which requires creating models using historical data of credit card transactions. A transaction processing system invokes the first component before approving a card transaction and emits the event for reactive detection.
The company is one of the leading credit card providers in the world and witnesses 10000 transactions per second. If a fraudulent transaction against a card is missed then there is a potential that the bad actor will subsequently use the same card for multiple fraudulent transactions. This means that if proactive component misses to detect a fraud transaction, the reactive one has to detect the same as soon as possible preferable within 60 minutes.
Strategy
This use case is suitable for stream-based/real-time processing because of following reasons:
This use case is suitable for stream-based/real-time processing because of following reasons:
- Processing of individual transaction is critical for the proactive component otherwise the transaction cannot be approved and will affect credit card usage by its holders.
- Processing by the reactive component should be done as soon as possible to reduce the blast radius of a bad actor. Anything beyond few minutes may not be acceptable for the company. Moreover, the availability of output is critical and if we process transactions in batches, each batch failure can result in larger financial impact.
- Also for reactive detection, approved card transactions should be made available within a few minutes and not after hours or days. This requires transaction processing system to provide data to reactive component either individually or in a group (reasonably small) which can be accumulated and processed for frauds in a few minutes.
4.2.2 Case Study 2
Problem
Tim is a carrier manager in an e-Commerce company. For the orders placed in the e-Commerce website, the company engages with third party carriers (100s of carriers) to ship the order from its warehouse to the customer location. Tim takes care of on-boarding these third party carriers and managing interactions with them on company’s behalf.
Tim is a carrier manager in an e-Commerce company. For the orders placed in the e-Commerce website, the company engages with third party carriers (100s of carriers) to ship the order from its warehouse to the customer location. Tim takes care of on-boarding these third party carriers and managing interactions with them on company’s behalf.
As part of the request to ship a customer order, carriers receive the package details like weight, volume, type of package, content category etc., pickup and drop locations. For all the deliveries of the package done in a month, carriers send an invoice to the e-Commerce company to pay for the services offered. Invoices are generated at the end of the month between 00:00AM and 01:00AM and the payment has to be made within 2-5 business days as per the agreement between a carrier and the e-Commerce company.
Carriers use the information provided in the shipping request (package details, pickup and drop locations) to generate invoice based on an agreed upon rate card. Typically, each month the e-Commerce company raises 3 billion shipping requests with multiple third party carriers. However, at the time of shipping requests, for around 2% of the packages, the e-Commerce company do not have all the information available which is needed by carriers for generating invoice and it is only available on the last day of the month. The e-Commerce company doesn’t know which information is mandatory for which carrier in the shipping request as it is based on the business process of third-party carriers in their company. Carriers used to apply some default value for such packages.
Recently, Tim received a request from multiple third party carriers that they want a capability built by the company so as to get missing information for these packages for accurate invoicing. The solution should allow carriers to generate invoices without delaying their SLA of 01:00 AM.
Strategy
The solution for this suits stream based processing because of the following reasons:
The solution for this suits stream based processing because of the following reasons:
- Invoice has to be created within a certain period, i.e. 00:00AM - 01:00AM, meaning that there is a strict SLA.
- Carriers would like to get quicker responses with lower processing time for individual or smaller number of packages so as to keep track of the progress during invoice generation (0:00-1:00).
- Batch processing for individual carrier or across carriers can increase the blast radius of typical “all or nothing” failures associated with such approach.
- The missing information is for 2% of total number of packages across multiple third party carriers. Hence the lookup against these packages for each carrier request whether its batch or stream will not be optimal without an indexed storage like DDB or ES. This further nullifies the typical benefit of batch based processing not needing high cost indexed storages.
5. Conclusion
In this blog, we looked at Batch Processing and Stream Processing. Batch processing is used on large data sets and executes on a periodic basis. Stream processing is used in near real-time use cases with strict SLAs. We outlined their advantages & disadvantages and added guidelines to choose between them on the basis of compute, latency, SLAs and data set size. Additionally, readers are also expected to apply their judgement apart from using this guidance in order to make a decision since problems can sometimes be nuanced and might not fit exactly into one category.
6. References
- Basic of Batch Processing (AWS Blog): https://aws.amazon.com/what-is/batch-processing/ (Reading Time: 10-15 mins)
- Beginner’s guide to Batch Processing (Talend Blog): https://www.talend.com/resources/batch-processing/ (Reading Time: 10 mins)
- Introduction to Stream Processing (Medium Blog): https://medium.com/stream-processing/what-is-stream-processing-1eadfca11b97 (Reading Time: 15 mins)
- Differences between Batch vs Stream (Medium Blog): https://gowthamy.medium.com/big-data-battle-batch-processing-vs-stream-processing-5d94600d8103 (Reading Time: 10 mins)
DISCLAIMER: The views expressed in this blog are solely those of the author and do not represent the views of Amazon. The information presented in this blog is for informational and educational purposes only. The author provides no guarantees or warranties regarding the accuracy, completeness, or usefulness of any content. Users acknowledge that any reliance on material in this blog is at their own risk. Amazon does not endorse any third party products, services, or content linked from this blog. Any links or reference to third party sites or products are provided for convenience only. Amazon is not responsible for the content, products, or practices of any third party site. The author reserves the right to make changes to this blog and its content at any time without notice. This blog may contain the author's personal opinions, which do not necessarily reflect those of Amazon.







